Marengo 3.0 menetapkan standar baru Video Intelligence dengan pencarian multimodal, dukungan video 4 jam, indeks 2× lebih cepat, dan performa unggul untuk produksi.
Video kini mencakup sekitar 90 persen data atau informasi dari seluruh data dunia. Namun organisasi atau perusahaan tidak dapat memanfaatkannya karena tidak bisa melakukan pencarian isi dan konteks dari video yang ada sehingga praktisnya, informasinya ada di sana tapi tidak kelihatan.
TwelveLabs menjawab masalah ini dengan membangun Video Intelligence yang benar-benar dirancang untuk mendulang informasi dari video, bukan fitur tambahan atau turunan model gambar.
Marengo 3.0 hadir sebagai model foundation video berkinerja tertinggi yang siap digunakan di lingkungan produksi. Berbeda dari pendekatan model yang dipaksa mendukung video, Marengo 3.0 memproses video sebagai sistem yang hidup dan dinamis. Model ini mampu memahami dialog, mendengar audio, melacak gerakan dalam rentang panjang, dan memahami konteks antar adegan hingga berjam-jam.
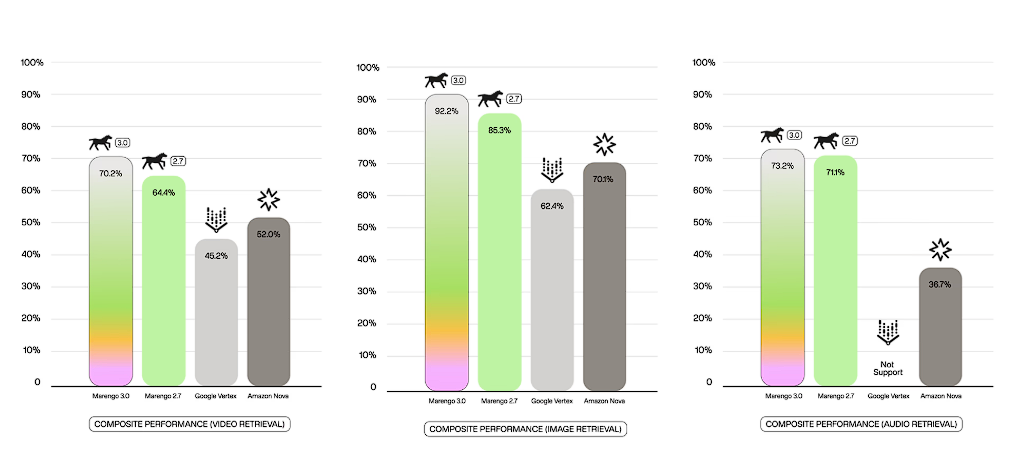
Dalam benchmark komprehensif yang mencakup pencarian video, gambar, teks, dan audio, Marengo 3.0 mencatat kinerja komposit 78.5 persen melampaui Amazon Nova (61.8%) dan Google Vertex (50.2%). Perbedaannya dalam pengujian produksi, Marengo 3.0 menghadirkan latensi yang jauh lebih baik, sementara kompetitor mengalami kegagalan menangani video panjang. Amazon Nova tercatat 10–15× lebih lambat pada video panjang dan gagal memproses konten 4K, sementara Google Vertex gagal memproses video lebih dari 60 detik dan tidak memiliki dukungan audio.
Kemampuan Marengo 3.0
Marengo 3.0 mengusung sejumlah kemampuan baru yang menjadi standar industri untuk analisis video modern. Peningkatan ini membuatnya lebih cerdas, lebih cepat, dan lebih ringan dijalankan dalam skala besar.
- Pencarian multimodal terkomposisi
Pengguna dapat menggabungkan gambar dan teks dalam satu permintaan pencarian, sehingga memungkinkan hasil yang jauh lebih presisi. - Pencarian entitas
Pengguna dapat menetapkan orang atau objek tertentu dan mencarinya ketika melakukan tindakan spesifik dalam video. - Dukungan video hingga 4 jam
Kemampuan ini meningkat dua kali lipat dari Marengo 2.7, sementara model lain tidak mampu memproses konten panjang. - Pengurangan penyimpanan hingga 50 persen
Embedding 512 dimensi memungkinkan efisiensi data jauh lebih baik dibandingkan Marengo 2.7 (1024 dimensi) dan Amazon Nova (3072 dimensi). - Indexing dua kali lebih cepat
Koleksi video dapat menjadi dapat dicari dalam waktu setengah kali lebih cepat dibandingkan sebelumnya.
Kemampuan ini bukan sekadar data benchmark, performanya telah terbukti di lingkungan produksi. Dalam sektor olahraga, media, dan hiburan, pelanggan mampu memangkas waktu persiapan konten dari berhari-hari menjadi menit. Di sektor keamanan dan pemerintahan, model ini membantu memahami rekaman sensitif dengan presisi tinggi. Dalam periklanan, Marengo 3.0 menghadirkan penempatan iklan kontekstual dan brand safety tanpa tinjauan manual.




















